Developing a fast matrix multiplication implementation on the CPU
Recently I took a course in parallel computing, where the focus was on using all the available resources we have on our computers. The course was tough but really interesting, so I thought it would be interesting to share some of the concepts learned there. The course, called Programming Parallel Computers, can be found online and there is an open version of it as well.
It’s helpful to have an example problem to go along with, so in this post I’ll be discussing matrix multiplication on the cpu. Assuming our matrices are squares of sidelength n, we need to do n3 operations on them. More importantly, there are many operations which we can do simultaneously, which makes this a very good example problem - maybe that’s why there are plenty of articles on matrix multiplication already. However, few of these go as deep as I’d like, so in this post I’ll try to continue where others have stopped. If you haven’t already, please read through Siboehm’s rather famous post on the topic here. I will assume that as prerequisite knowledge.
Baseline
for (int y = 0; y < ny; y++)
{
for (int x = y; x < ny; x++)
{
float sum = 0;
for (int k = 0; k < nx; k++)
sum += mat[k + nx*y] * mat2[x + nx*k]
result[x + y*ny] = sum;
}
}Here is the baseline implementation. I’ll start measuring benchmarks when they don’t start to take half an hour on my testcases, but this runs quite poorly. Siboehm’s blog post didn’t use any preprocessing, but to get any reasonable results we are going to need it. One preprocessing step we can most certainly do to speed this up considerably is transform the matrix 2 in advance. The preprocessing takes a bit of time, but it is in the order of O(n2) whereas our matrix multiplication is in O(n3). This means that it doesn’t take that much time compared to the multiplication itself. The preprocessing saves us from reordering the loops, which will come handy later. This gives us about 2x speedup in my experience.
Starting the optimization
Let’s first tackle vectors. Modern computers have vector registers which can do multiple independent operations in parallel. At the time of writing this the widest we have in any computer is AVX-512 registers, which are 64 bytes wide. Since one float is 4 bytes, we can fit 16 floats into one register. This allows us to do 16 independent operations on a single instruction. Needless to say, this should speed up our solution by approximately 16x. We can access vector instructions by defining them in gcc like so: typedef float float16_t __attribute__((vector_size(64)));. I’m running these on a machine that supports AVX-512. If you don’t have that available, you can also use AVX2. These vectors will allow us to do the following:
for (int y = 0; y < ny; y++)
{
for (int x = y; x < ny; x++)
{
float16_t sum = {};
for (int k = 0; k < nx4; k++)
sum += mat[k + nx4*y] * mat2[k + nx4*x];
result[x + y*ny] = SUM16(sum);
}
}Here of course we need to modify our preprocessing so that it packs the values into vectors. I find it quite helpful to always try to visualize my problems, this is what I’ve done here. In the 3D diagram below, the top and right face represent our input matrices, while the front face is the result matrix. To calculate the orange area, we need to multiply the blue areas together and add them up. For this reason, it makes sense to vectorize these, and that is exactly what you can see in the code above.
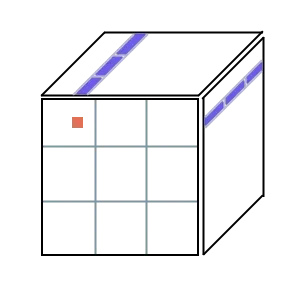
One more thing we can do to easily get more performance is to use many threads. We can calculate each of the output blocks outlined in grey simultaneously, as they do not depend on each other. Depending on the amount of threads and the amount of blocks we have, this should give us around 8-16x speedup. With all of these improvements, my testcase of 9000x9000 matrix multiplication runs in 10 seconds on my machine. The reason why we split the thread usage like this, instead of only by columns for example, is to optimize cache usage. One thread will reuse the same values many times, so this is faster than other segmentation patterns.
Here is where most articles on this topic stop, but to really get everything out of our computers, we need to go much deeper. The following optimizations take a bit more effort, but the payoff is truly worth it.
Keeping data in registers
Memory bottlenecks are really common on problems like these, as it is quite slow to load memory from ram into registers. In fact, there seems to be around 50x difference between computational performance and memory transfer speed. Cache helps us a little bit here, but for best performance it is quite important to try to keep as much data in registers as possible. Using a value in a register takes one clock cycle, while even loading from L1-cache takes approximately 2.5 cycles. Let’s redo our vectorization from just a while ago, and try to calculate a bigger chunk of the result at once.
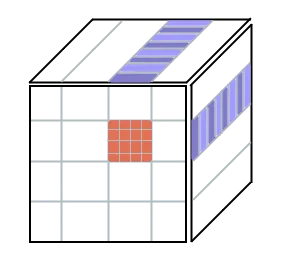
If we instead vectorize our input matrices the other way (vertically), at any given time we can read 16 floats from matrix one and 16 floats from matrix two, and use these to calculate 16 * 16 = 256 values into the result matrix. The illustration below tries to explain this idea. Now we of course need to do 16 more iterations in the horizontal dimension, as we aren’t vectorizing that way anymore, but the payoff is worth it. Many machines have 32 vector registers that we can use, so allocating 16 of those to store our intermediate results as 16 float -wide vectors seems reasonable enough.
Now we only need to discuss how to actually compute all of these values. There are two main ways to efficiently calculate the results needed. We can either use the permutate-assembly instructions or the broadcast-instruction. Here I’ll explain the broadcast version as it is simpler to understand.
The term broadcast refers to the assembly instruction vbroadcastss, which takes a float and widens it to a float16, copying the same scalar value to all positions in the vector. This allows us to compute all the combinations of the 16 vectors. In this image I’m using 4 wide vectors, to simplify the diagram, but the same concept extends to wider ones as well.
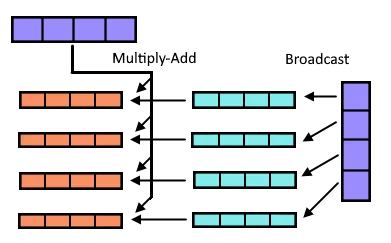
After we have loaded the purple vectors from memory, we go through every one of them sequentially. In the image this is done for the vertical one. For each element in the vector, we broadcast it to a vector full of that value (shown in aqua) and multiply it with the other vector to get the result (orange). We sum the results of every input matrix column as we did previously. This technique gives us a comfortable 6x speedup over the last version, putting us at 1.6s for the testcase. The inner-most loop of code for this in C++ could look something like this:
float16 sums[16];
for (int i = 0; i < 16; i++)
sums[i] = VEC_0;
for (int k = 0; k < WIDTH; k++)
{
const float16 val1 = mat[k + x0*WIDTH];
const float16 val2 = mat2[k + y0*WIDTH];
for (int i = 0; i < 16; i++) // The compiler will unroll this
sums[i] += val1 * val2[i];
}
for (int i = 0; i < 16; i++)
sumsMem[i] = sums[i];We make a stack array vec sums[16]; of the vectors to force the compiler to store them in registers during the loop, and only put them into memory after we have summed everything.
Segmentation
As our matrices get bigger, we start to lose the ability to hold data in caches. Even though we try to leverage caches by calculating values using same columns, it could be gone by the time we get back to it again. This starts to happen precisely when the matrixies A and BT from our calculation A*B get too wide, meaning that the loop in the code sample above needs to iterate many times. Fortunately, we can split the matrix into pieces.

In the image above, we again want to calculate the front face. However, we can calculate each of the colored regions separately and sum them together at the end. For my benchmark of a 9000x9000 matrix, I found a segment size of 500 to be a good fit, giving us 18 segments to iterate through. This technique speeds up our matrix multiplication algorithm by approximately 2x, lowering the time to 0.72. It’s worth noting that we can expect a speedup here only if we were previously memory-bound rather than computation-bound. This is important, because this optimization also adds extra overhead: at the start we need to set the result matrix to all 0s so that we can sum to it. This time memory still was the bottleneck, but it is important to try to analyse where we should do improvements.
One more improvement
I previously said that most machines capable of doing AVX-512 instructions have 32 vector registers (at least my machine has), and our technique of calculating 16x16 values only uses 16 of those registers. We can do better. I tested some different block sizes, and a quite good one is to calculate a 9x48 block at once. It’s the same idea, just extended to allow us to use 27 vector registers. We don’t actually want to use all of our 32 registers for storage, since we also need to load the data from memory which requires some registers. The 9x48 block has 3 vectors horizontally and 9 scalar values vertically (if we look at the broadcast picture above). Applying this optimization to our matrix multiplication brings the time down to approximately 0.57 seconds, of which the actual multiplication takes 0.46 seconds.
Conclusion
I also experimented with doing a Z-curve on the matrix, but after all of the other optimizations it didn’t give a speedup. It might be that memory is not an issue anymore, or the cpu might just like the predictability of simple iteration. Either way this is where I will end the optimization of this function.
Still, with smart preprocessing of the data and smart register and cache usage, we have managed to speed up our function by couple orders of magnitude. While matrix multiplication is largely a solved problem, I find these techniques really fascinating. Hopefully you did too!